Project III: Statistical Classification (Ric Crossman)
There are many real-world situations in which we might encounter some variation on the following problem. We want to know what category an object belongs to, but we cannot determine this directly. Instead, we need to consider observed characteristics the object possesses, and use those characteristics to decide what category the object is most likely to belong to. An (extremely) incomplete list of such situations is given below.
· Medicine, in which disease types might be the categories, and symptoms might be the observed characteristics.
· Economics, in which general situations for next year's economy ("boom", "recession", "depression", etc.) might be the categories, and economic properties/measurements of this year's situation might be the observed characteristics.
· Ornithology, in which bird species might be the categories, and properties of the bird (colour, size, song, location found, etc.) might be the observed characteristics.
· Finance, in which credit ratings might be the categories, and income, expenditure, capital holdings etc, might be some of the information used to decide on a rating.
Having taken Statistical Modelling 2 (a pre-requisite for this project), you are aware of how linear regression can be used to provide an expected value of a continuous response variable, given values of either continuous or categorial variables. Classification focuses instead on providing expected values of a categorial variable. This one apparently small tweak completely changes our approach.
Group Project
The group project will be centred on the basic nature and concepts of
classification, with a focus on one of the most fundamental and
(comparatively!) simple classification methods: logistic regression. This is a
classification method which allows us to estimate the probability of an object
belonging to one of two categories.
By the end of the group project, students will have learned:
· How a classification method is defined,
· The reasons why linear regression cannot be used for a binary outcome variable,
· The relationship between linear regression and logistic regression,
· How logistic regression models can be interpreted,
· How logistic regression models can be evaluated.
Mode of Operation and Evidence of Learning for the Group Project
The project will involve reading up on the underlying theory of logistic
regression models, focussing on their mathematical theory and structure and how
to effectively and accurately interpret such models. Students will demonstrate
their understanding by exploring examples and theoretical applications of
logistic regression models, and clearly communicating
this exploration in both written and oral formats.
Individual Project
The individual project will build on the knowledge you have gained in the group
project, and will explore additional advanced topics.
There are a large number of potential topics to be
explored here, including:
·
Generalised logit model regression: an
extension of logistic regression which allows probability distributions for the
category of an object to be generated, given the object's observed
characteristics. This is done by comparing odds ratios of each category to a
single reference category. One possible extension to this topic would be
considering the issue of overdispersion.
· Classification trees: an alternative to the regression approach, in which directed acyclic graphs are mathematically constructed to give us what we might consider flow charts. Each non-leaf node represents an observed characteristic, each edge from such a node is labelled with one or more values that observed characteristic can take, and the leaf nodes represent categories. Such a graph can therefore be used to label an object with a category. There are many different ways to build such trees, depending on the choice of splitting rule, which determines which observed category is the most valuable to assign to each node. One possible extension to this topic would be random forests.
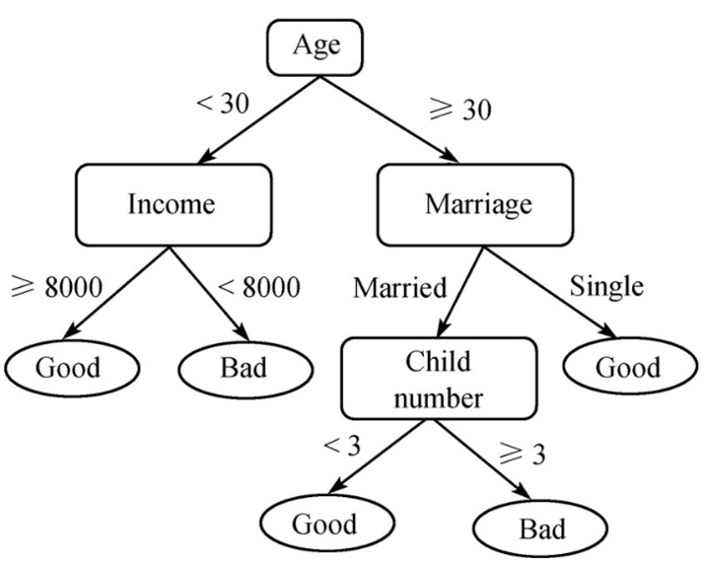
Example of a decision tree for credit scoring (taken
from this paper)
· Naive Bayes Classifiers A set of approaches to classification which commonly use Maximum Likelihood Estimation to determine the most likely category of an object, under the assumption that, given the actual value of the category, the probability distributions of each observable property are independent of each other. This assumption simplifies the process of creating the likelihood function, which - as one would expect from a Bayesian process - is then combined with a prior distribution for the categories in order to produce a posterior distribution for the categories given the observed characteristics. One possible extension to this topic would be Non-naive Bayes Classifiers.
Other forms of classifier could also be considered, and/or multiple classifiers might be compared. Toy data sets will be available to allow small-scale applications of these approaches in practice. Students wishing to apply classification approaches to larger data sets would be encouraged to seek out such a data set themselves ahead of beginning the individual project.
Mode of Operation and Evidence of Learning for the Individual Project
This project will involve reading up on the underlying theory of classifiers
beyond logistic regression, focussing on their mathematical theory and
structure and how to effectively and accurately interpret such models. Students
will demonstrate their understanding by exploring examples and theoretical
applications of classifiers beyond logistic regression, and
clearly communicating this exploration in both written and oral formats.
Pre-requisites
Statistical Inference 2, Statistical Modelling 2
Web Resources
The Elements of Statistical
Learning, Hastie, T; Tibshirani, R; Friedman, J;
2nd edition 2009, Springer.
An Introduction to Statistical Learning,
James, G; Witten, D; Hastie, T; Tibshirani, R; 2nd
edition 2021, Springer.
Further Information
If you would like more information about this project, or to discuss its scope
and/or prerequisites, or if you just have a related question, please let me
know at richard.j.crossman@durham.ac.uk.